米国パテントの翻訳(2)
ー特許用英日翻訳ソフト「PAT-Transer Ver.3.0 /ej」の活用例ー
特許文に特化した翻訳ソフト
本連載の第4回「米国パテントの翻訳」で(株)ノヴァの「ポケットトランサーVer.2.0」の翻訳事例を中心に紹介したが、(株)ノヴァの製品には、別に特許文に特化した翻訳ソフト「PAT-Transer Ver.3.0 for Windows」(2000年10月3日発売)がある。
ここでは、ポケットトランサーとの共通の機能や操作はできるだけ避けて、「PAT-Transer Ver.3.0 /ej」の独自機能を中心に紹介する。
翻訳する原文としては、インターネットでダウンロードしたもの、あるいはOCRで取り込んだテキスト形式のファイルが予め用意されるものとして話を進める。
注)「PAT-Transer Ver.3.0 /ej」にはブラウザーで翻訳対象領域を選択しておいて、特許翻訳ツールバーで対訳ボタンをクリックするだけで対訳モードに読み込んで翻訳を自動実行するという簡単な方法もある。
「PAT-Transer Ver.3.0」の独自機能としては、次のような機能が挙げられる。
(1) 特許前処理機能
特許原文テキスト"***.txt"に対して、特許前処理機能を最大限に引き出すために前編集が必要な場合もある。このテキストが対訳モードに読み込まれるとき、特許前処理機能が自動実行され翻訳ファイル"***.eph"が生成される。
(2) 自動訳例反映機能
慣用文を訳例ファイル"patent.out"に登録しておくと、特許前処理で自動処理され、一致する原文を見つけると訳文エリアにその訳を設定してロックをかける。
(3) 対訳データベース機能
翻訳効率と翻訳精度を高めるための独自機能で、標準搭載のデータベースに加えてユーザーデータベースに訳例を登録できる。訳例を蓄積することで使い勝手が増し、自然な人間翻訳に近づけることができる。
(4) 特許後処理機能
訳文に特許独特の表記(墨付き【】)や用語(「請求項1」など)に置き換え、前処理で原文に付加した$saidなどの$付き単語から$を取り除く。
(5) 後編集機能
環境設定により使い慣れたワープロやエディタが使用できる。訳文ファイル(特許後処理)"***.pat"の最終仕上げ編集を行う。
また、スクリプト言語NovaScriptが装備されているので、内蔵の自動処理操作が実行でき、またユーザーが独自のスクリプトを作成して自動処理に活用できる。
このように、「PAT-Transer ver.3.0」の独自機能には、訳文をできるかぎり日本特許の様式や言い回しに合わせようとする機能と、翻訳効率と翻訳精度を高めようとする機能の二つがある。
技術的内容の理解を専らとする技術者には前者の様式や独特の言い回しはそれほど重要ではないだろうが、文書の形式を重んずる用途向けには有用な機能といえる。
以下、翻訳作業の流れに沿ってポイントを解説する。
特許原文ファイルの前編集と特許前処理
原文テキストファイルは、場合によってはワープロやエディタにより前編集を行う必要がある。また、特許前処理のための環境を整えておく必要がある。特許前処理の対象になる項目は、次のようなものである。
・特許請求範囲の始まり
・全角文字の半角文字への変換
・挿入構文
・ピリオドで終わる略語
・訳例反映
特許前処理機能は、特許原文ファイル、または前編集を行ったファイルを開く(対訳モードへ読み込まれる)ときに、自動的に実行される。
(1)特許請求範囲の始まり
PAT-Transer/ejでは、特許の「特許請求の範囲」を翻訳する際、特許特有の言い回しや表記をサポートしている。この項目の始まりを示す表記はさまざまであるが、PAT-Transer/ejでは、以下の書き方を【特許請求の範囲】の始まりとしている。
WHAT IS CLAIMED IS: WHAT I CLAIM IS:
[Ww]hat is claimed is: [Ww]hat I claim is:
[Ww]hat we claim is: I claim:
We claim: Claim:
注)[Ww]hatは、Whatまたは、whatのどちらの表記を使うこともできると言う意。
明細書が「米国特許の書式に準じた」ものの場合、前編集はほとんど必要ないが、このような書き方が含まれない、例えばヨーロッパ特許庁(EPO)の書式では、前編集で"Claim:"の直後に"I claim:"など、上記のいずれかを挿入しておく必要がある。
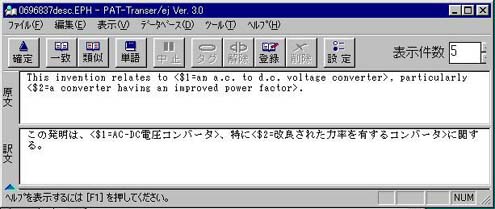
図1 翻訳後の「対訳モード」の画面
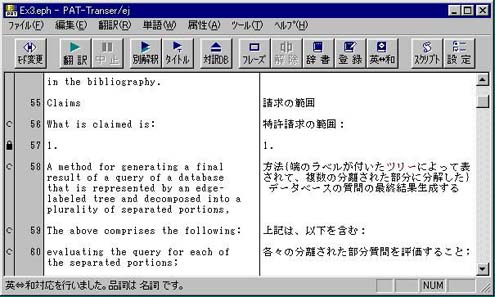
このようなテキストファイルをPAT-Transer/ejで対訳モードで開くと、特許前処理が実行され、【特許請求の範囲】の始まりと判断した以降の文章には、クレーム文の属性をあらわす記号Cが属性エリアに表示される。また、数字だけの文はそのまま訳文エリアに書き込まれ、文番号がロックされる。翻訳後の「対訳モード」の画面は図1のようになる。
(2)全角文字を半角文字に変換
一般に英文には全角文字は含まれていないが、OCRで読み込んで変換した原文ファイルには、ときどき記号などが全角になっている場合がある。
PAT-Transer/ejでは、特許前処理で変換テーブルを参照して全角文字を半角文字に置き換える。この変換テーブル(zen2han.tbl)は、ユーザーカスタマイズ可能なファイルで、対象の文字を追加するなどの編集ができる。
(3)挿入構文に対する処置
英文の挿入句は、一般にコンマで囲んで示される。しかし、コンマには挿入以外にも並列や同格を導く役割があるため、コンマによる挿入句を挿入句として認識できず、本来まとまっていなければならない挿入句の内容がバラバラになったり、不適当な位置に挿入句の訳が出ることがある。
挿入句に対する前編集には次の方法がある。
方法1:挿入句を括弧でくくる
コンマによる挿入句を括弧でくくり直すことで、挿入句を正しく認識させることができる。
●前編集した文
"A plurality of sliding and fixing elements are mounted on the bottom surface of the pallet and are each connected (preferably at their center) to a compressed air system through a pneumatic control unit."
●前編集後の翻訳結果
「複数の滑走および固定素子は、パレットの底表層に載置して、空気の制御装置による圧縮空気システムに接続している(好ましくはそれらのセンターで)各々である。」
括弧でくくった挿入句は、英文の直前の単語に対応する訳語の後(上記の例では、
"connected"の訳語「接続している」の後)に訳される。
方法2:挿入句をフレーズ指定する
この例では、"preferably at their center"を「副詞句」に指定して翻訳すると正しく訳出される。
(4)ピリオドで終わる略語
"gen_abbrev.tbl"と"non_end_abbrev.tbl"ファイルには、ピリオドで終わる略語の一覧が含まれている。通常、PAT-Transer/ejではピリオドの後にスペースがあると文分割を行うが、略語は単語の最後がピリオドであるが、文分割すべきではなく、特許前処理では、このファイルに含まれる単語の後は、文分割を行こなわないように操作する。
略語を追加したい場合は、市販のワープロまたはエディタで、"gen_abbrev.tbl"または"non_end_abbrev.tbl"を読み込んで編集し、上書き保存すればよい。
(5) 訳例反映
特許文には独特の言い回しの長文が含まれるが、このような文は、翻訳ソフトで構文解析して翻訳するよりも、対訳ファイルを参照して一致する原文に対して訳文を自動設定する「訳例反映」機能の方が適している。
"patent.out"ファイルは、「訳例」ファイルで、"--"記号、原文、訳文の順番で対訳が書かれている。
特許前処理では、"patent.out"ファイルを参照して一致する原文が見つかった場合、対応する訳文を訳文エリアへ自動設定して、文にロックをかける。ロックがかかった文は、一括翻訳や一文翻訳を行っても、再翻訳されない。ロックを解除すると再翻訳することができる。
注)「訳例反映」機能は、ポケットトランサーにもあるが、このように特許前処理で自動実行されるものではない。
訳例ファイルの例は次のようなものである。
●原文
"While the invention has been described with reference to a specific embodiment, the description is illustrative of the invention and is not to be construed as limiting the invention."
●訳文
「本発明については、特定の実施例に関して説明したが、この説明は例示的なものであり、本発明をこれに限定するものではない。」
後に説明する対訳データベースとの違いは、対訳データベースを使った翻訳が、文分割されて対訳モードに読み込まれた文を翻訳する際に使用する機能であるのに対し、訳例反映は、長文が分割される前の原文に対して実行される点である。そのため、翻訳反映機能を使えば、簡単に適切な翻訳が行える。ただし、訳例反映は、訳例ファイルの文と翻訳中の文がまったく同じ場合にだけ適用される。
訳例反映用に対訳ファイル、"patent.out"が用意されており、このファイルはユーザカスタマイズ可能なファイルである。
訳例ファイルの編集には、次の2つの方法がある。
方法1 PAT-TranserVer.3.0 /ejによる訳例ファイル編集
patent.outファイルを対訳モードに読み込む。文書の最後に移動し、新しい文番号を作り、原文となる英文を入力する。訳文エリアに訳文となる日本語文を入力する。訳例ファイルがいくつもあるときは、新しい文番号を作り、上記手順を繰り返す。保存先をdataフォルダーに指定し、「用途(A)」を「対訳ファイル」(特許後処理なし)にし、ファイル名がpatent.out になっていることを確認したら上書き保存する。
方法2 ワープロやエディタで訳例ファイル編集
patent.out ファイルを開き、"--"記号、原文、訳文、改行コードの順番で入力する。
特許前処理ではこの他、次のような作業が自動実行される。
(6) 文の分割
特許前処理では、特許独特の長い文を分割して、その際、必要になる副詞句、主語などを自動的に補う。
(7) タイトル、箇条書き、クレーム文
読み込み時にPAT-Transer/ejが【特許請求の範囲】の始まりと判断した以降の文章には、クレーム文の属性をあらわすCの記号が付加される。
同様に、箇条書き、またはタイトル文と判断された文には属性エリアに箇条書きは□、タイトルはTと記号が付く。
(8)英語のまま
数字の羅列などが\[ \]の記号で囲まれることがある。この記号で囲まれた文字列は、英語のまま訳出され、翻訳速度を高める。
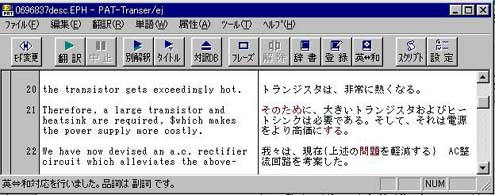
(9) $付き単語
いくつかの単語には$が付加される。これらの単語は特許翻訳用に特別に処理されるので、$を削除するなど編集することはできない。
$が付加される単語には、$said, $whichなどがある。
図2 $付き単語の例
(10)ロックがかかる文
いくつかの文番号の前には鍵形が付き、文がロックされる。ロックされた文は、ロック解除を行わないと再翻訳できない。ロック/ロック解除は、文番号の前でマウスカーソルが鍵の形になったところでクリックすると実行される。また、ロックがかかった文には、特許前処理して対訳モードに読み込んだときに、訳文エリアに翻訳結果が表示される。ロックがかかる文は、訳例反映を実行した文、数字の羅列のような文である。
翻訳
ツールバーの翻訳をクリックすると翻訳が開始され、翻訳結果が訳文エリアに次々と表示される。翻訳後の単語の対応と訳語の変更、訳語の学習、単語の登録については、ポケットトランサーと同様の操作である。
翻訳精度を高めるため、ユーザー辞書や対訳データベースの充実が重要である。
特に、対訳データベース機能はPAT-TRanser独自のもので、データベースの蓄積により翻訳効率、翻訳精度を高めることができる。
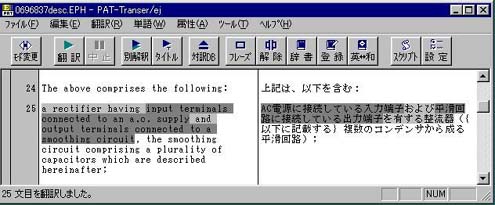
(1)並列表現のフレーズ指定による翻訳
次のようなandで結ばれた並列表現の例では、フレーズを3個、2階層のフレーズレベルまで指定しないと正しい翻訳結果が得られない(図3)。
The above comprises the following:
a rectifier having input terminals connected to an a.c. supply and output terminals connected to a smoothing circuit, the smoothing circuit comprising a plurality of capacitors which are described hereinafter;
図3 並列表現のフレーズ指定による翻訳例
(2)対訳データベースを使った翻訳
対訳データベースに頻繁に使用される人間が訳した自然な訳文を登録しておくと翻訳効率と翻訳精度を高めることができる。
定型化されることの多い文は、変化する部分を明示した「文型」として登録する。文型に合致すれば、元の文から変化した部分だけを機械翻訳して、その結果を訳文の対応する位置に埋め込むので、文全体を機械翻訳するよりも、より人間の翻訳に近い結果を得ることができる。
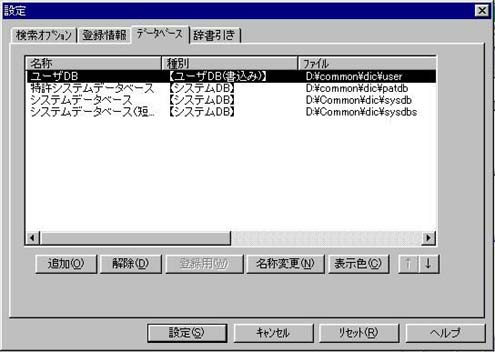
PAT-TRanser/ejには、「特許システムデータベース」、「システムデータベース」、「システムデータベース(短文)」が装備されているので、必要に応じて設定する。
登録用の対訳データベース(ユーザーデータベース)は、ユーザーが必要に応じて対訳文を登録できるもので、翻訳作業の効率化高精度化に欠かせない。
以上の対訳データベースは優先順位を指定することができる。
図4 対訳データベース優先順位の指定
また、どのような検索方法で翻訳するかを指定できる。「完全一致文検索」、「文型一致文検索」、「類似文検索」、「機械翻訳」の順に翻訳が実行される。完全に一致する文が見つからなかった場合は、「文型一致文検索」が実行され、文型の同じ文が見つけられなかった場合は、「類似文検索」が実行され、類似文が見つからなかった場合は、最後に「機械翻訳」が実行される。例えば「類似文検索」を使わないときはチェック項目をはずしておけばよい(図5)。一文翻訳で、シフトキーを押しながら文番号をクリックすると、強制的に機械翻訳が実行される。
図5 どの検索方法で翻訳するかを指定
対訳データベースへ対訳文を登録する、つまり、「ユーザーデータベース」を作成するには次のように簡単な方法で実行できる。例えば、図6のように変更可能な部分(例、an a.c to d.c voltage converter)を選択して「タグ」ボタンをクリックすると原文の該当部分が<$1=an a.c to d.c voltage converter>のようにタグでくくられる。これに対応して予め訳文エリアに求めたい訳文を作っておき、その訳文で「AC-DC電圧コンバータ」を選択してタグボタンをクリックする。タグが複数ある場合は、タグ番号が一致していなければならない。入力が正しく行われたら「登録」ボタンをクリックして必要な登録情報を付記した後に登録する。
図6 ユーザーデータベースの作成例
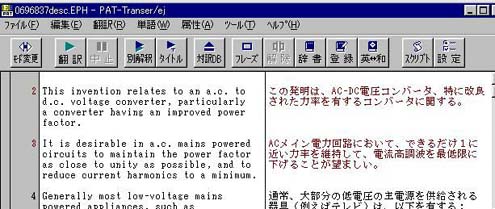
次に、文型一致文検索がオンの状態で翻訳を実行すると、図7のような直訳調でない翻訳結果が得られる。「完全一致」文や「文型一致」文では文番号と訳文の文字色が指定の色に変わる。
図7 直訳調でない翻訳の例
特許後処理
特許後処理は、「テキスト出力」メニューで「用途(A)」を訳文ファイル(特許後処理)"***.pat"または対訳ファイル(特許後処理)"***.out"を選択して保存すると自動的に実行され、次のような処理が行われる。これらの処理は主に日本特許庁の書式に合わせるための操作であり、技術的内容の理解を専らとする技術者にとっては、それほど重要なこととではないかもしれないが、書式が重視される用途向けには有用な機能であろう。
(1)前処理で付加された$の削除
前処理でいくつかの単語が$付きの単語(例、said->$said)に変換されたが、原文どおりの$のない単語に戻される。
(2)墨付き括弧【】
特許特有の表記に墨付き括弧【】があるが、後処理では、【特許発行日】、【発明の名称】のように特許特有の文字列を囲む。
(3)【特許請求の範囲】文中の数字の表記
【特許請求の範囲】の始まりを示す表現の後に現れる文の先頭にある数字には、ロックがかかり、後処理の対象になる。後処理で数字は【請求項1】、【請求項2】に置き換わる。
図8 【特許請求の範囲】文中の数字の表記
(4)自然な日本語に修正する
訳出された日本語を自然な文体に修正する。
使い慣れたエディタやワープロによる後編集
メニュー「テキスト出力」でテキストファイルを作成すると、作成されたファイルの内容を表示する/しないを確認するメッセージが表示される。ハイを選択すると、ファイルの内容がViewTranserに表示される。
しかし、ViewTranserは、テキストファイルの表示と印刷の機能だけでエディタ機能がないので、後編集を行うには使い慣れたエディタやワープロを使えるように設定を変更する必要がある。
設定を変更するには、「ツール」ー「スクリプト」ー「特許表示ツールの設定」でViewTranserの使用をいったん解除した後、ツールメニューで同じ要領でお気に入りのエディタやワープロを指定すればよい。
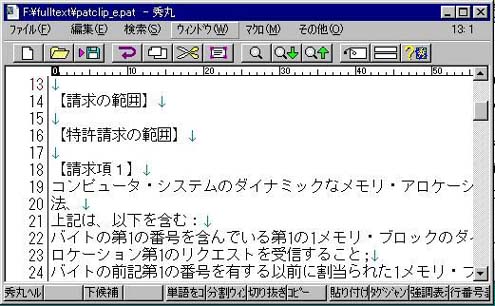
秀丸を指定し、「ファイル」ー「テキスト出力」で出力結果を表示させた例を図9に示す。
図9 「ファイル」ー「テキスト出力」での出力結果例
このようにして作成された訳文ファイルは、第5回「米国パテントのデータベース作成」で紹介したのと同じ要領でデータベースのレコードとして利用できる。