2ー4
米国パテントのデータベース作成
これまで、米国特許庁のホームページから米国パテントのフロントページやフルテキストをダウンロードし、それらを日本語に翻訳する方法を
紹介してきた。これらのファイルをデータベースとして検索/閲覧するには
AfterDJのようなソフトが有用であることはすでに述べた。
ここでは、フロントページ、フルテキスト、および日本語翻訳ページが相互に関連付けられ、また完成したデータベースがLANによりファイル共有されたり、Web公開により情報共有できるように、データベースソフトのファイルメーカーPro4.1
ver.1(
Mac版)を用いて、独自のパテントデータベースを作成することにする。
データの準備
(1)一括ダウンロードする際に用いたものでも、ダウンロード後に作成したものでもよいが、特許ファイルの
特許番号を羅列したxxxxx.txtというコンマ区切りテキストファイルを用意する。xxxxxは識別のための任意の番号である。
(2)
ダウンロードしたデータファイルは、それぞれ識別番号xxxxxの付いたフォルダーにfrontpage、fulltext、
imagesというサブフォルダーを作って、それぞれの特許番号毎のhtmlファイルやjpegファイルが収納される。
(3) サブフォルダー
frontpageのhtmlファイルから特許番号(usps)、発明の名称(title)、要約(abstract)、国際分類(ipc)、発明者(inventors)、出願人(assignee)、参照文献(references)などを抽出したタブ区切りテキストファイルxxxxx.tsvを用意する。
TSVファイルの例としては、以下のようなものである。
表1 タブ区切りテキストファイルの例
3938045 Transmitter for frequency shift keyed modulation A
transmitter for communicating binary data by minimum shift keying
(MSK) wherein control of the radiated spectrum of the transmitted
signal is achieved by controlling the rate of switching between mark
and space frequency signals such that the MSK switch acts as an
equivalent of a low pass filter. H04L27/12 Mathwich; Howard Robert
(Cherry Hill, NJ). RCA Corporation (New York, NY).
3946220 Point-of-sale system and apparatus A point-of-sale terminal
system including one or ・・・・
(4)一方、サブフォルダーfulltextのhtmlファイルからは、翻訳支援ソフトを活用して、発明の名称と抄録のテキストファイルxxxxx翻訳.txtを作成しておく。
データベースファイルの仕様と作成
データベースファイルには次の三つのファイルを作成し、リレーショナルデータベースとする。
(1)一覧表示ファイル(UsPatents.fmj)
uspn、ipc、
inventors、assignee、titleおよび和文title(発明の名称)のフィールドをリスト形式で閲覧するするためのファイルである。完成時点の画面の例を図1に示す。
図1 データベース画面(一覧表示ファイル)
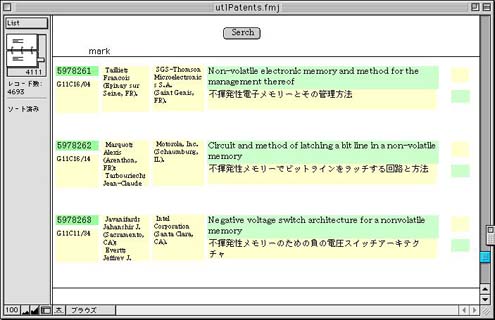
検索用のレイアウトは別に用意し、Serchボタンを押すと検索専用画面が開くようにする。検索可能なフィールドは、上記フィールドの他にabstractと和文の抄録フィールドでも自由語により内容の検索ができるようにする。同様に検索条件入力時の画面を図2に示す。キーワードの例は、和文titleフィールードの「電源」である。
図2 検索条件入力時の画面
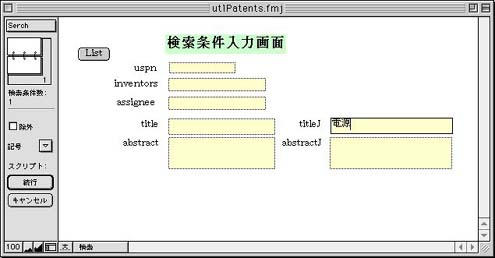
(2)英文アブストラクト閲覧ファイル(UsPatentsAbstracts.fmj)
検索結果を英文のフロントページの 内容で閲覧するためのファイルで、参照文献(references)ファイルも表示され、そのレコードがデータベースにある場合は、参照文献の特許番号をクリックすると直接そのレコードに跳ぶこともできる。またこのページからFulltextボタンをクリックするとFulltextサブフォルダーのhtmlファイルをInternet
Explorerで開くことができる。
(3)和文抄録閲覧ファイル(UsPatentsAbstractsJ.fmj)
和文タイトルと和文抄録を閲覧するためのファイルで、特許番号のフィールドにはボタンを設定し、クリックすると一覧表示ファイルに跳ぶようにする。また和文タイトルにもボタンを設定しクリックすると英文アブストラクト閲覧ファイルに跳ぶようにする。入力専用のレイアウトを別に用意し、翻訳支援ソフトを活用して作成したテキストファイルxxxxx翻訳.txtからコピー&ペーストで入力したり、一括でファイルを読み込んだりする。
UsPatents.fmjではリレーションを次のように定義しておく(図3)。重複レコード検索で用いる「共通」フィールドはグローバルタイプとして定義する。
「Serch」や「Fulltext」のボタンを作り、スクリプトを割り当てて操作性を高めている。「Fulltext」のスクリプトには、Internet
Explorerに対しApple
Eventの送信コマンドが含まれ、またhtmlファイルへのパスを探索するためにUseLand
Frontierが使用されている。
図3 データベース画面(リレーション定義)
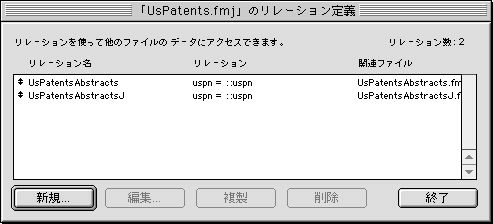
データの取り込み
ロット毎に以下の手順を繰り返すことにより、データベースにデータが蓄積される。
手順1 マスターファイルである UsPatents.fmj を立ち上げる。
手順2 xxxxx.txt
を「コンマ区切りテキスト」、「新規レコードとして追加」で取り込む。
手順3 UsPatentsAbstracts.fmjをトップにする。
手順4
xxxxx.tsvをファイルタイプを「タブ区切りテキスト」として、「新規レコード として追加」をチェックして取り込む。
手順5 UsPatentsAbstractsJ.fmjをトップにする。
手順6 xxxxx翻訳
.txtを開き、UsPatentsAbstractsJ.fmjの該当フィールドにカット&
ペーストする。またはファイルを一括して取り込む。
実際に作業を進めると、作業ミスなどにより同じ特許番号がダブって入力されたりすることは、往々にして起こる。このような時、重複レコードの検索ができれば、データベースの保守を行う上で便利である。このような重複レコードの検索を行うには、表2のようなスクリプトを定義しこれを実行する。重複するレコードにはx印が付けられ、xが入力されているすべてのレコードを検索し「対象レコード削除」を実行すれば重複レコードは一括削除される。また、uspnで昇順または降順でソートした後、重複レコード確認レイアウトでx印のついたレコードを確認しながら適宜削除してもよい。
表2 重複レコード検索のスクリプト
全レコードを対象に
ソート [ 記憶する、ダイアログなし]
レコード/検索条件/ページへの移動[最初の]
全置換[ダイアログなし、「重複」、「""」]
フィールド設定[「共通」、「uspn」]
Loop
レコード/検索条件/ページへ移動[最後まできたら終了、次の]
If[「共通=uspn」]
フィールド設定[「重複」、「"X"」]
Else
フィールド設定[「共通」、「uspn」]
End If
End Loop
検索実行[記憶する]
検索の実際
初期画面として先に示した図1のようなリストが表示されている。そこでSerchボタンを押すと図2のような検索条件入力画面が現れる。
例として、TitleJのフィールドに「電源」と入力して、検索を実行すると図4のような検索結果が得られる。
図4 データベース画面(検索結果表示)
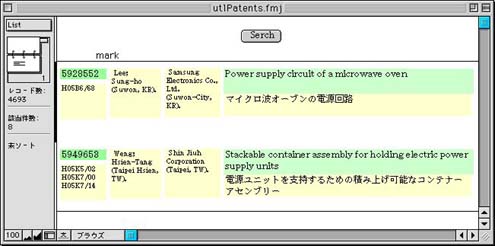
ここで英文タイトルのフィールドをクリックすると図5のようなAbstract画面が開く。また、和文タイトルをクリックすると図6のような和文抄録画面が開く。
図5 データベース画面(英文Abstract表示)
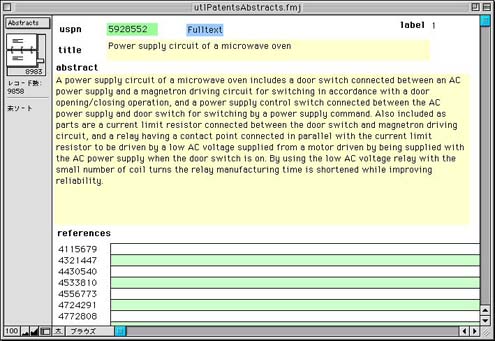
図6 データベース画面(和文抄録表示)
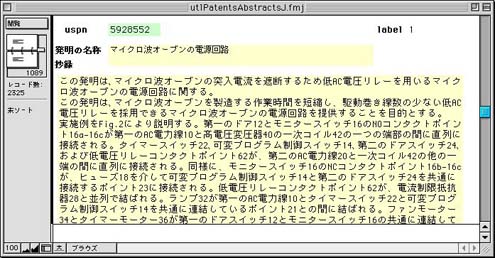
英文Abstract画面と和文抄録画面は、そのタイトルフィールドをクリックするとお互いに画面が切り替わる。特許番号フィールドをクリックすると一覧表示画面(図1)に戻る。
英文Abstract画面で、FulltextボタンをクリックするとInternet
Explorerでサブフォルダーfulltextにあるhtmlファイルを開くことができるが、これにはスクリプトの他にUserLand
Fronteerのプログラムを必要とするのでMacの環境でしか実行できない。Internet
Explorerは予め立ち上げておく必要がある。
次回予定:「米国パテントデータベースのファイル共有とウェブ公開」
参考文献
(1)「ファイルメーカーPro」ユーザーズガイド
(2)佐藤武久「電子技術者のためのパソコン利用術 第13回 データベースとデータベース・ソフト」日刊工業新聞社「電子技術」1997年11月号、p89-94
(3) 同上記事はhttp://homepage2.nifty.com/sato032/でも閲覧可能